如何更好地构建知识体系?
坦白地说,这个问题又大又玄。我也没有能解答这个问题的信心与万能灵药。只是前两天看了一些元认知领域的书与文章,有了一些新的视角,和大家分享一下。
那么就要引出我们今天的主角 - DIKW 模型
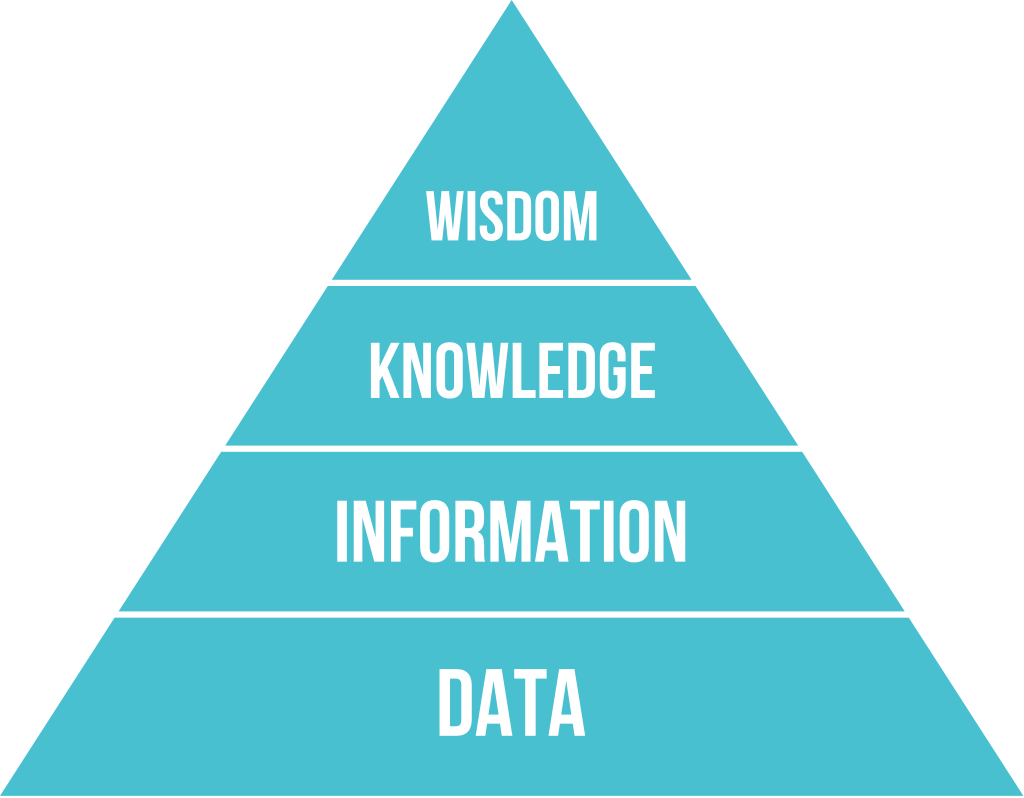
简单来说,DIKW 模型将我们广义上的知识分为 Data - Information - Knowledge - Wisdom 四层金字塔结构。
这个模型告诉我们,我们认知与学习,是遵循一个获取数据 - 提炼信息 - 总结知识 - 通悟智慧的过程,每一层都比上一层更为深入。
那么接下来,我们一层一层进行解释。
(为了统一,以下所有名词均使用英文)
Data 如何成为 Information
要回答这个问题,首先就要理解 data 与 information 二者的差别。
让我们以“气象站”举例。
一般而言,每个城市的不同区域都会架设百叶箱,里面的温度计会定期记录温度数值——每一个数值就是一个 data。
如果你把某个时间段所有的温度数值进行汇总,并进行一定的处理(比如:加权平均),就可以得到这个时间段的温度——这就是 information。
单个的 data 其实没啥意义,information 才具有意义。当你在气象网站上查到当前的气温,这是 information 而不是 data。
再比如用翠翠的网站举例。
每一个访客访问到我的网站时,网站统计程序都会自动记录一条访问记录——就是 data;而当把每一天的所有访客数值加起来,就可以得到每一天的“访客数”——infomation。
——讲到这里,不如自己想一想有什么其他的 data 与 information 的例子。
。
想
。
想
。
想
。
也许你会想当然地认为从 data 到 information 是一个很显而易见的容易过程——相比于其他几步确实相对容易,但也没那么容易。
这一步主要的困难在于,筛选出真正的 data,去除掉无用的噪声与干扰信息——尤其是对于数据量特别特别多的情况下,如何用更好更自动化地方法去除这些干扰信息,便是很重要且棘手的一个问题。
还是用气象站举例,比如某百叶箱坏了,统计出了个 50 度的温度——那是必然不应当被作为加权平均的 data 中的,一旦被加入,则会污染所得到的 information;如果我的网站把爬虫也算作访客,所得到的每日访客也会出奇地高。
另一个困难则在于,我们所获取的数据往往是“有偏”的,如何评估与修正这些偏差,则又是一个棘手的问题——因为我们自身是很难意识到我们的偏差的,想要评估与修正则更是难上加难。更何况我们很多时候只愿相信我们所相信的,本能抗拒与我们直觉相违背的结论。
一个很好用的例子是微博与公众号下面的“控评”:由于评论区中负面的评论被后台过滤掉,我们并不能接触到那些负面的 data,使得我们获取的 data 本身就是有偏的:全部是正面的评论以及大家的点赞,可想而知,如果以此作为输入的 data,自然最终也会提炼出错误的结论。
值得一提的是,从 data 到 information 这一步是需要异常小心且谨慎的——我们之前也提到,从 data 到最后的 knowledge 是一个单向的过程。如果这一步出现明显的偏差,就好像从源头被污染的水,之后自然会得到错误的结论与观点。
Information 如何成为 Knowledge
还是之前的例子:如果你汇总了某个城市连续多年的“每日气温”,那么你就可以大致得出一个结论:这个城市的气温是炎热还是寒冷,是否适宜居住。这个结论就可以算是 knowledge;通过对比一段时间内翠翠网站的每日访客数,可以大致计算出翠翠网站的访客趋势,什么样的文章访问量高,这样的结论也是 knowledge。
那么具体说来,information 和 knowledge 又有什么区别呢?
首先,从生命周期来说,information 通常“短命”而 knowledge 则通常是“受用终生”的:以几年的维度来看,城市某天的气温并没有什么意义,但这个城市“适不适合居住”却是在较长的时间维度上都有参考价值的。
其次,对于 knowledge 来讲,是可以整理成体系的:还是用城市做例子,将和“城市”有关的知识整理起来,就可以形成一个介绍城市的“体系”:从某些方面进行入手,就可以系统化这个城市的相关知识。

由此衍生而来,我们现在所学习的理学,文学,工学农学医学等等,也是被编作体系之后,可以系统学习的 knowledge。
从 information 到 knowledge 所面临的困难则在于体系化。如何将碎片化的 information 中梳理为体系化的 knowledge,是对我们逻辑能力和思考能力的考验。
就好像我们的知识体系是一座图书馆,现在新来了一些 information,如何将他们分门别类安放在合适的位置形成 knowledge,就是对我们知识体系本身完备性的一大考验。如果 information 无处安放,自然也就暴露出离自己知识体系的不完备。
更具体地,如何从城市的温度,地理,人文等信息,总结出一个可以介绍一个城市的维度体系,就是这一层次所需要关注的问题。
Knowledge 如何成为 Wisdom
层次逐渐深入,关于 knowledge 和 wisdom 的探讨,就要更加玄学和难以理解一点,也自然要更费一点口舌。我打算从两个角度来分别进行阐述。
首先,从学科的角度来讲,我们之前提到,不同学科其实都是成体系的 knowledge。那么相对应的 wisdom 就是在这之上的“元学科”,他们通常在探讨学科设置的意义,是对学科内容的进一步反思,同时也是站在顶层设计者的视角去反思意义。
用相对具体的例子说一说。例如在产品领域,knowledge 更像是在说某 APP 所具体实现的功能,例如微信的联系人功能,私聊功能,群组功能,pyq 功能等等,而 wisdom 探讨的则是“微信的本质是什么(让人与人之间互相连接)”,“为什么要设计朋友圈功能”等等的问题。
所以,从我们日常认知的角度来讲,wisdom 要更加“玄学”和“顶层”一点。
另一个角度则是从 What-How-Why 三类问题的视角出发:我们一般可以把学习中遇到的问题分为 What How Why 三类问题
What 型问题一般在问“是什么”,即弄清楚某个东东是什么样子的,有什么用处?有什么特性?有什么语法?
How 型问题则一般是问“如何”,即某东西是如何实现的,如何运作的。要弄清这样的问题,一般就需要对某一领域足够了解,明晰其内部机理。
Why 型问题则一般在问“为什么”,例如:某东西为什么要采用这样的设计,为什么不做成另外对样子等等。想弄懂 why 型问题,则必须在上一问题的基础上进行反思。
这么说还是有点空泛,就用我相对熟悉的计算机领域举个例子,不同领域的读者可以尝试使用你所在的领域进行代入。
近些年来前端框架层出不穷,其中很火的一个框架叫做 React。那么对于 React,其三类问题就分别是这个样子:
What:React 有什么样的优缺点
How:React 内部是如何实现的
Why:为什么要做 React 这样一个框架;React 是为了解决怎样的问题;React 又导致了什么问题,需要怎样进一步解决——这往往又是新框架诞生的基础
而通过这样的层次划分,knowledge 与 wisdom 的区别则显而易见:knowledge 对应着 what 类与 how 类问题,而 wisdom 则对应 why 类问题。
*注:对于这三类问题的归类似乎有争议,有学者认为 what 类问题对应着 information,但我个人比较同意编程随想的观点,即短命类 what 问题对应 information,而有效期较长的 what 类问题则对应 knowledge。

也正是因为如此,wisdom 类的 why 问题往往没有标准答案——因为这类问题本身就已经直指到了设计本身,难以有很明确的标准答案——有的只有,能回答得上与回答不上的区别。
而进一步的,也只有不同学科间,不同领域间的 wisdom 之间可以互相启发。近些年来的很多交叉学科,就是将不同领域间的 wisdom 相互融合,用在一个领域的视角进入到另一个领域,从而获得不同的启发。这也是为什么我们需要接触不同学科的原因——就好像是另一双看世界的眼睛一样,能让我们从另一个视角发现不同的 wisdom。
与前两层所对逻辑与数据的洞察的相对硬性的要求不同,从 knowledge 到 wisdom 的最大难点在于:好奇心。往往我们与 wisdom 失之交臂的主要原因并不是力所不能及,却是内心缺乏一个在问“为什么”的声音,缺乏一个敢于质疑与疑问的好奇宝宝。
再聊聊如何构建知识体系
现在我们知道了我们是如何将外界的输入转化为我们自己的 wisdom 的,那么接下来的问题就是如何更快,更好地进行这一转化过程。
那么答案其实就明确了:缺啥补啥 ww
在工程学中我们会强调“瓶颈”这一概念:对于流水线生产的装备,往往制约其效率的是某一环节,一旦改善了这一环节,通常会使得效率上一个台阶。
比方说就拿电脑启动来说。一些老式的电脑启动往往需要大几十秒,但瓶颈其实往往出在硬盘而非我们所以为的 CPU 显卡之类的“核心”上。往往花个小几百换个 SSD,开机速度就能从原来的几十秒瞬间变成三四秒——解决了瓶颈,其实就相当于解决连整个问题。
而自己的知识转化瓶颈在哪一步,也许就只有自己才知道了。
有的人缺在缺乏持续性的,高质量的 data 与 information 作为输入,或者是在当今海量的 data 中迷失了自己:对于前者,需要通过有经验的大牛,切入高质量的信息来源;对于后者,则需要对自己接触的 data 进行有效的控制与筛选。
有的人则由于思考不足,尽管知道很多 knowledge,却难以变成 wisdom 从而有所输出,或是指导自己的学习与生活:如果是这样,就需要有意识地训练自己问 why 的能力并加以回答与输出。
但我所见的大多数人的困难则出现在从 information 到 knowledge 一步:由于现在网络上的时效性短的吵杂信息越来越多,我们越来越难以从 information 中快速有效地提取出 knowledge,抑或没有较成熟的知识体系以安放由于网络碎片化而零落的各种 information:如果如此,则需要避免浮躁,多用时间在知识本身的内化上,而不是仅限于“我知道了”而已。
互联网的出现大大加速了 data 与 information 的传播速度,广度,却使得其深度大大降低,很多文字与资讯要么停留在 information 层面(热点,八卦类等),要么过于碎片而难以体系化(短科普视频,信息流等),而真正可被内化为 knowledge 层面的成体系的信息则越来越少。
没啥建议,少刷手机多看书。
最后的一点彩蛋是,回想一下这篇文章的标题,“如何更好地构建知识体系”——很明显,这是一个 how 型问题。那么相应的 why 型问题——“我们为什么要构建知识体系”的答案是什么呢?既然都看到这了,那这个问题对你来说,必然是有原因的。为什么呢?就留给屏幕前的你思考吧 w
预祝,新年快乐
顺颂冬祺



已有 8 条评论
mata-wisdom, 赞.
神奇的自动获取头像
抱歉之前重复提交了,我不知道怎么删除
没事的我帮你删掉了呢
信息管理中,有一个经典的理论:Fact - Data - Information - Knowledge - Intelligence
好的我去了解一下!OωO
想起了之前记下的信息处理的流程,潜移默化中似乎和这里的 DIKW 模型有点关联哈哈哈
https://blog.izgq.net/archives/1239/
是的!www
而且事实上,很多时候工具只是那个 "information" 和 "what",背后需要掌握的其实是那个 "how" 和 "why"。就好像总会被问道学入门计算机要学 python 还是学 C 之类的——但是其实感觉编程语言啊什么的都是工具罢了,背后的算法哇设计思想哇才是真正的屠龙的东西ww